
Update 20 Apr 2016: Check out the paper on arXiv (PDF)
Summary
Word-RNN (LSTM) on Keras with wordified text representations of Metallica’s drumming midi files, which came from midiatabase.com.
- Midi files of Metallica track comes from midiatabase.com.
- LSTM model comes from Keras.
- Read Midi files with python-midi.
- Convert them to a text file (corpus) by my rules, which are
- (Temporal) Quantisation
- Simplification/Omitting some notes
- ‘Word’ with binary numbers
- Learn an LSTM model with the corpus and generate by prediction of words.
- Words in a text file → midi according to the rules I used above.
- Listen!
A Quick look on things (copied-and-pasted from my previous post)
LSTM
LSTM (Long Short-Term Memory) is a type of RNN. It is known to be able to learn a sequence effectively.
RNN
RNN (Recurrent Neural Network) is a type of deep learning neural network. See this post by WildML for further understanding.
Keras
Keras is a deep learning framework based on Theano and Tensorflow. I used Theano as backend but this shouldn’t affect the output.
Another quick look on things
Metallica
Metallica is an American heavy metal band formed in Los Angeles, California. Metallica was formed in 1981 when vocalist/guitarist James Hetfield responded to an advertisement posted by drummer Lars Ulrich in a local newspaper. Wikipedia
Why Metallica?
Because I found quite enough number of midi track of Metallica – more than any other artists so far. Also the drum tracks in Metallica are relatively consistent. The simplification in the preprocess would also make sense for Metallica drum tracks according to…… my brain.
Preprocess – How to Model a rhythm representation into a text?
LSTM models are basically about time-series modelling, i.e. 1-D data. In my previous work, it was straightforward how to model a chord progression as a text (so that I didn’t even mentioned about ‘modelling’). I converted the midi tracks into a symbolic, 1-D data to deal with it as a text.
Drum track is not a 1-D

No it isn’t as you see above. This is so called a piano-roll view. Y-axis is pitch, x-axis is time, and each note represents different part of drum. Here, blue:kick, green:snare, yellow-or-olive-or-whatever:(opened) hi-hats, and red:crash cymbals. Yes, this is a piano-roll view of the drum track of Master of Puppet – from 0:28 in this live:
It is not 1-D as drummers are using their arms and legs simultaneously.
First, Quantisation and Simplification
Quantisation is to put the notes at certain timings, and only at certain timings. Nice explanation from mididrumfiles.com. It’s just a rounding function in time axis. So I quantised the midi files by 16th notes, assuming Lars Ulrich is not playing otherwise – it introduces some errors, especially there are triplets.
Further simplification I did is to limit the types of notes: a kick, a snare, open hi-hats, closed hi-hats, three tom-toms, a crash, and a ride: 9 notes in total. Using the General-MIDI drum map it is expressed as below:
allowed_pitch = [36, 38, 42, 46, 41, 45, 48, 51, 49] # 46: open HH
drum_conversion = {35:36, # acoustic bass drum -> bass drum (36)
37:38, 40:38, # 37:side stick, 38: acou snare, 40: electric snare
43:41, # 41 low floor tom, 43 ghigh floor tom
47:45, # 45 low tom, 47 low-mid tom
50:48, # 50 high tom, 48 hi mid tom
44:42, # 42 closed HH, 44 pedal HH
57:49, # 57 Crash 2, 49 Crash 1
59:51, 53:51, 55:51, # 59 Ride 2, 51 Ride 1, 53 Ride bell, 55 Splash
52:49 # 52: China cymbal
}
My encoding scheme (midi→text)
The basic idea is to represent the information of all True or False (played or not played) of every notes at a time with a single word. The words are rather self-explanatory:
‘000000000’ : nothing played
‘100000000’ : kick is played
‘1000000001’ : kick and crash played
‘0101000000’ : snare and open-HH played
Obviously 1 is True and 0 is False, at their dedicated places with a rule of:

with ‘Bar’ added for the segmentation of measures.
Corpus looks like this:
0b010000000 0b010000000 0b000000000 0b010000000 0b010000000 0b000001000 0b000000000 0b000001000 0b010000000 0b010000000 0b000000000 0b010000000 0b010000000 0b000001000 0b000000000 0b000001000 BAR 0b010000000 0b010000000 0b000000000 0b010000000 0b010000000 0b000001000 0b000000000 0b000001000 0b010000000 0b000000000 0b000000000 0b000001000 0b000000000 0b000001000 0b000001000 0b000000000 BAR 0b100000001 0b000000000 0b000000000 0b000000000 0b010000001 0b000000000 0b000000000 0b000000000 0b100000001 0b000000000 0b000000000 0b000000000 0b010000001 0b000000000 0b000000000 0b000000000 BAR …
where a prefix 0b is added to specify it’s kind of a binary number.
LSTM Structure
I applied word-RNN here. Some numbers are..
- 60 songs for training data
- Number of words: 2,141,692 (including ‘BAR’ in every 16 words)
- Total number of words: 119
- 119 out of 2**9==512 possibilities.
The code is the same as I used for LSTM Realbook:
model = Sequential()
model.add(LSTM(512, return_sequences=True, input_shape=(maxlen, num_chars)))
model.add(Dropout(0.2))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(512, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(num_chars))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
The results
It didn’t end up learning the structure of bars and 16-notes after the first iteration.
0b000000000 0b010100000 0b100000000 0b100010011 0b000000000 0b000000000 0b100001010 0b100000000 0b000000000 0b010000000 0b000000000 0b101000000 0b000011000 0b000000000 0b001001101 BAR
0b000000000 0b000000000 0b001000000 0b100000000 0b100000001 0b010000000 0b000100000 0b000000000 0b000001100 0b000000000 0b000000000 0b101000000 0b000000000 0b011000000 0b001000000 0b000000000 BAR
0b100000000 0b000000000 0b000001000 BAR
0b000000000 0b100100000 0b010100000 0b100100000 0b010100000 0b101000000 BAR
0b000000000 0b000000000 0b000000000 0b100000010 0b000000000 0b010100000 0b000000000 0b101000000 0b000000000 0b101000000 0b000100000 0b011000000 0b100000001 0b000000000 0b000000000 0b100100000 0b011000000 0b000000000 0b001000000 0b101000000 0b000000000 0b010000001 0b010000000 0b101000000 0b100100000 0b100000000 0b100000000 0b000000000 0b000000000 0b101000000 0b010010000 0b000000000 0b101000000 0b101000000 0b000000000 0b000000000 0b000000000 0b101000000 0b000000000 0b000011000 0b000000000 0b000000000 0b100100000 0b000010000 0b100100000 0b000000000 0b100000000 0b001000000 0b000000000 0b101000000 0b000000000 0b000000000 0b000000000 0b000000000 BAR
0b000000000 0b101000000 0b100000001 0b000000000 0b000000000 0b000000000 0b000100000 0b000000000 0b000000000 0b000000000 0b000000000 BAR 0b000000000 0b000000000 0b000000000 0b100000000 BAR
After 45 iterations it looks more structured. (I added \n for better understanding)

After 60 iterations it became bit more structured.

Okay, it’s boring, let’s listen to the rhythm.
First, I add a score for this track:

It looks like a proper drum score. You can listen to it below:
I ran 60 iterations with diversity parameters of [0.5, 0.8, 1.0, 1.25, 1.5]. I’ll present 10 tracks – with all the diversity parameters x [30th, 60th] iteration result.
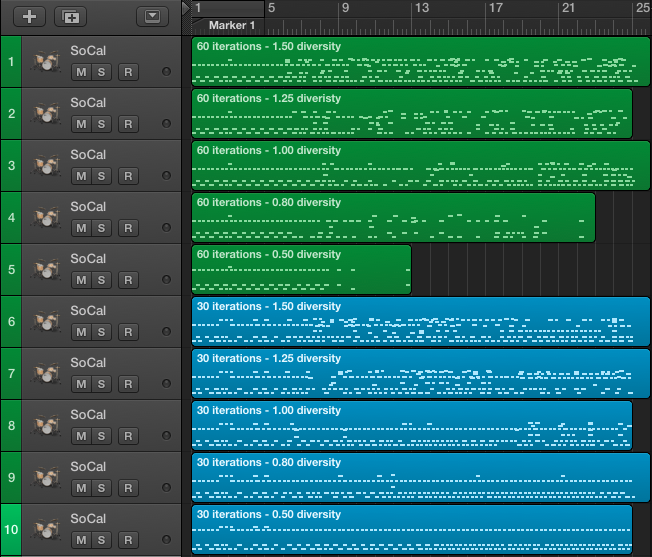
With the diversity value of 1.50 and 1.25 the track sounds bit too virtuosic. Track 3, 8, 9, 10 are boring but probably more makes sense.
Track 8 and 9 are interesting, to some extent is has regular patterns with kick, snare, hi-hats + crash cymbals.
Do they sounds like Lars Ulrich?… Perhaps not yet.
Discussion
- Looks like I have to fine tune the diversity parameter to get more reasonable drum tracks.
- The proposed encoding scheme – based on nine binary digits – seems making sense.
- Probably learning with different segment would lead a whole, complete track with a proper beginning and ending.
- I don’t think it is deeply understanding the structure – the regular patterns of kick, snare, hi-hats, and the meaning (except track 8 and 9). At least it didn’t come to me that easily.
- It would be also cool if I had more data with other bands to have some pun fun. E.g. Rage Against the long short Term Memory.
- What I wanted to do is to do it with jazz drum tracks so that I could combine them with LSTM Realbook. Is there any good (and hopefully free) resources for it?
Code & dataset
Dataset is now shared in my repo. Will share the code soon.

I stumbled upon to visit your post.
Well I don’t describe myself as an machine learning professionalist, but I think no one can deny that you’ve made such a great thing, which shows what machine learning can do in our real life with a very fun way.
LikeLike
I feel flattered, thanks for your kind comment!
LikeLike
Very cool, I’ve learned a lot! Keep rocking!
LikeLiked by 1 person
Thanks and happy to hear that it helped. And yeah, keep rocking!!
LikeLike
The encoding scheme you choose is a cool idea! And the LSTM certainly has learned the right patterns. Nice work!
LikeLiked by 1 person
Hey this is very cool! It would be awesome to create a tool using this method for generating drum tracks based on the bands someone likes.
LikeLiked by 1 person
Thanks! The Drummer track in Logic X is already very cool, but more works to appear soon 🙂
LikeLike
Can you provide the midi->text conversion code?
LikeLike
Sorry, I can’t because I don’t have the right.
LikeLike
Thank you.
I really enjoyed your work and would like to contribute with it and use it as a basis for new research (citation is your job).
Could you just tell if you created the algorithm or if you used a ready tool?
LikeLike
Oh, excuse me, I got confused with chord progression work. I coded it by myself using https://github.com/keunwoochoi/LSTMetallica/blob/master/drum_note_processor.py . Sadly I can’t find the script I used. I’m afraid I removed it while cleaning up the folder. (I don’t wanna believe it.. I never delete codes, just found out this.)
In the file above, there are two classes – note and note list. The methods of Note_List is ordered as it’s supposed to be used. add_note, quantise them, simplify drum events, and return as text. I hope it helps.
LikeLike
Nice work. I am little confused on how to generated text from midi files. Can you help?
LikeLike
I would not listen to ROCKMUSIC or any music of the devil!! I would pray about all video games, movies, and tv shows and not watch anything of the world.
LikeLike