
I’m glad to announce that our recent work, DrummerNet, was accepted to ISMIR 2019. My deepest gratitude goes to my great co-author, Kyunghyun Cho. A huge thanks to Chie-Wei Wu (now with Netflix) for discussions, comments, and insights, too.
DrummerNet
What is that?
DrummerNet is a deep neural network that performs drum transcription (gets drum track audio, outputs its drum note annotation – when which drum components was played).
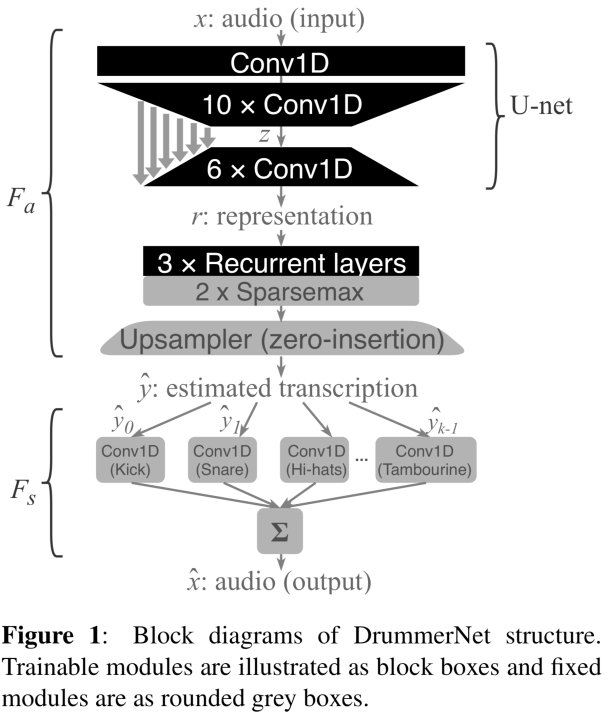
What’s so special?
We trained DrummerNet in an unsupervised learning fashion. In other words, no drum annotation (transcription) is needed.
Like how?
By letting it reconstruct the input drum audio using known drum component waveforms and an estimation. In the block diagram above, the grey boxes are not trained. The block boxes are trained, which comprises the transcriber.
Does it work well?
Yes.

You should be careful though to interpret it. This is the case of ‘cross eval’ scenario, where all networks are trained on some other datasets, then tested on SMT (no fine tuning). Hence it’s more realistic and it evaluates the generalizability.
And that’s the reason I was interested in unsupervised learning. When I was deciding the research topic, I was actually not interested in a certain task. I only cared about what can be done and only done with a large un-annotated dataset (=unsupervised learning) because, in MIR, annotated datasets are TINY. Like, tiny as a really tiny thing. Like… 20 songs!
What was the trick?
I didn’t test anything but U-net for the analysis part. For me, its implicit multi-resolution nature fits so well.
I didn’t test 2-dim representation as input. To be honest, I think they might work better because KD/SD/HH are pretty easily distinguished visually.
SparseMax was very important as you can see in Ablation Study section of the paper.
Unsupervised Learning
Hey hey hey, unsupervised is the way to go especially in MIR. The reality has shown us so far that we won’t get enough annotated data anyway. These days, the get a linear improvement of a deep neural network, we need exponentially increased dataset.
DrummerNet paper reviews and my response
Ok, this is the fun part! See the review I had from ISMIR along with my response.
# Meta review
> This is a meta-review.
>
> This paper proposes an automatic drum transcription (ADT) method called DrummerNet that combines an analysis module with a synthesis module in a unified autoencoder-type network. The proposed method was comprehensively evaluated and the results are promising and convincing.
>
> All reviewers agree with (strongly) accepting the paper. The proposed method based on the integration of synthesis and generation is technically novel. As some reviewers pointed out, the missing acoustic information problem in generation and the semi-supervised property should be discussed more carefully and clearly in the camera-ready manuscript.> My comments as a reviewer are as follows.
>
> I enjoyed reading the paper. It is well written and organized. This is the first study that uses the autoencoder-type network for ADT. The paper should be accepted due to its significant scientific contribution.
😉
> The proposed method is technically sound, but it should be called a semi-supervised method, NOT an unsupervised method, because isolated drum sounds are used as templates for synthesis. The authors should clarify this in abstract and Section 1 and amend the title. There are some semi-supervised ADT methods, so the authors should make a more specific title indicating the paper content.
I wouldn’t agree, for me that sounds like a bit too wide definition of semi-supervised learning. Although its definition may vary, some sources clearly define it as using labelled datasets + unlabelled datasets together. As long as the goal of DrummerNet is NOT to find the right templates, using templates itself shouldn’t make it semi-supervised learning. I know there are some works calling something similar semi-supervised, but also there are some other works calling exactly same thing unsupervised. I’m of an opinion of the latter idea.
> The neural integration of analysis and synthesis has recently been studied in some fields (e.g., computer vision and automatic speech recognition). Please refer to such attempts, e.g.,
>
> (a) Semi-supervised End-to-end Speech Recognition Using Text-to-speech and Autoencoders, ICASSP 2019.
> (b) Cycle-consistency Training for End-to-end Speech Recognition, ICASSP 2019.
(Hm, these works were published after my submission, and I already mentioned a paper from computer vision though..)
(a) shares a similar idea, but it uses both {pair, unpaired} datasets for both {ASR, TTS} (and that’s why, again, it’s called SEMI-supervised). This is different from DrummerNet. In DrummerNet, you need more stuff to make sure it outputs transcriptions only after trained with drum stems — no supervision on y, the label (=transcription). Not quite similar problem.
Also, the given situation is different – for both ASR and TTS, there are annotated datasets that are large enough for successful supervised learning that is deployable in a realistic scenario. Meanwhile, for drum transcription, SMT is like 100 drum loops with 3 drum kits. …and we use it for training/validation/test..
(b) is more similar to DrummerNet than (a) is. But it’s still not that similar. So, probably not.
> The authors should discuss a critical limitation of the integrated analysis and synthesis approach in Section 1. In principle, it is impossible to completely reconstruct original signals only from musical scores because musical scores have no acoustic information (e.g., timbres and volumes). Therefore, a core of the proposed method is that the synthesis module is trained to generate onset-enhanced spectrograms obtained by significantly losing acoustic information. This idea is very close to the text-to-encoder (TTE) approach proposed in (b) instead of the text-to-speech (TTS) approach.
Isn’t it the scope of transcription task, not the limitation of DrummerNet? And isn’t removing redundant information == feature extraction? DrummerNet isn’t about making drum tracks sound better so I wouldn’t call it losing information. All classification tasks are ultimately reducing the input data into N one-hot-vector.
Also, DrummerNet actually uses volumes (or velocities). It’s actually even better than supervised learning approach, and potentially more and more. Transcription annotation does NOT include acoustic information. However, we need those information AS WELL to synthesize well. Analysis-sythesis transription is, hence, already estimating volumes, and potentially can extract richer information — while supervised learning of transcription is upper-limited to the task of finding the onset positions.
# Review 1
> The paper provides a method to train a machine learning system, in this case a neural network, in the case where data is scarce in an unsupervised manner. The task addressed is perennial in MIR, drum transcription. The main idea behind the paper is not: synthesis has been used before to address the lack of data annotation.
Paper which use similar ideas:
> > Carabias-Orti, Julio J., et al. “Nonnegative signal factorization with learnt instrument models for sound source separation in close-microphone recordings.” EURASIP Journal on Advances in Signal Processing 2013.1 (2013): 184.
Salamon, Justin, et al. “An Analysis/Synthesis Framework for Automatic F0 Annotation of Multitrack Datasets.” ISMIR. 2017.
Um……… not really. First, Ok. DrummerNet synthesizes drum signals. But not for generating more training data. That’s what Mark Cartwright, or Richard Vogl did (and I mentioned in the paper as another important direction).
Drummer synthesizes drum audio tracks based on resulting drum transcription of its transcriber module.
> Furthermore, it is interesting to mention Yoshii’s drum transcription which uses adaptive templates, which is another case of unsupervised drum transcription. This paper doesn’t appear in the state of the art as well as some other drum transcription papers published in recent years.
Yes, it’s what I mentioned in the introduction with citing it ([44]).
> Integrating the synthesis part into a fully-differentiable network is an excellent idea. However, I have some concerns with some tweaks which were introduced to improve performance, regarding their differentiability. First, is the CQT transform differentiable? This is needed to compute the cost between on x and \hat x, respectively on their onset enhanced CQT spectrum. How is this implemented within pytorch, which does not have CQT?
Pytorch doesn’t have official CQT (or pseudo-CQT as mentioned in the paper), so I implemented. (Also provided in the source code).
> The heuristic peak picking method is introduced only in the evaluation. Is this function differentiable?
It is only in the evaluation (hence it’s fine even though it’s not differentiable).
> The loss is computed on an analogue task to drum transcription: reconstruction. The onset enhancing is meant to improve a bit the similiarity between the tasks, however, there are many factors missing: how the velocity (intensity,amplitude) of the transcribe events influence the transcription, particularly when they are masked by other events?
That’s when DrummerNet makes mistakes. Section 4.4(last paragraoh) and Figure 7 is about that problem.
> Some SoA based on NMF uses tail models to account for the dissimilarity between the decay and the attack. How does that influences this paper?
- My guess: for kick/snare/hi-hat, it seemed fine (the problem of variations in the envelope curve is already part of the problem DrummerNet has to solve to do the job right).
- My opinion: That model is a simplfied approach, and I think we should try something more generalizeable than that aspect.
> What if only 3 drum classes are used? How does that impact the f-measure?
I didn’t get it exactly – we’re using 3 classes only already.
> Electronic kits are not used here and the datasets are scarce regarding this type of music which has a diverse and different timbre. How do authors plan to deal with this problem.
Several opinions.
– For the ‘kits’ Synthesizer module, it’s trivial to add electronic kits.
– But I understand the raised concerned is more about how it’d work with electronic drum stems.
– One thing — I would plan to see it as a less difficult problem because by definition, it is way easier to synthesize a realistic, high-quality electronic drum tracks. It’s not the case when it comes to recordings of acoustic drums — the randomless and various modification that are introduced during recording and producing process is the most natural augmentation of data. Probably for the reason, real drum recordings would provide more information than synthesized drum tracks.
> The starting paragraph in 4.3 is not clear and it should be rewritten. It’s not clear what authors want to address with that evaluation? The system seems to be retrained on test/train collections of SMT for a fair comparison with state of the art?
Fair enough, will update. Quick note — we do not re-train DrummerNet on SMT, and that’s what transfer learning scenario or Eval Cross meant in the cited review paper by Wu et al.
The last phrase of 4.3 overhypes the proposed system, which is another ML system after all and can suffer from overfitting and domain-mismatch. There will always be some mismatch between training and testing data and it is very difficult to predict how a system would perform on unseen future data. Strong claims need strong evidence which is not justified here: DrummerNet is easier to train (doesn’t need annotated data) but it is prone to overfitting as any ML system.
Partly because of what I answered right above, I don’t think it is an oversell to say so. Naturally, although an ML module with supervised learning would not overfit to the training set with a proper set split, it only fits to that dataset at its best. When that dataset is really big (E.g., ImageNet), we don’t need to worry if it only had fitted to a certain distribution only (I.e., it’s almost ‘true’ distribution!)
The recent deep supervised learning approaches for drum transcription have done a very good job (2016-now). Their within-split sets performances, which what people have reported, are excellent. But their cross-dataset performances, which I used in Figure 5, are slightly less good. How slightly? Well, large enough so that DrummerNet (2019), and NMFD (2012.. yes. 2 0 1 2 !!!) outperformed. It wouldn’t happen if we have an ImageNet-sized annotated dataset. The reality is, SMT dataset is 130 mins. MDB is 20 mins. ENST is 61 mins. And they are quite different to each other and only representing a small subset of drum stems.
Training data can represent the real world scenario in some cases. When training sets are tiny, however, we can’t expect that would happen. And the annotated sets for supervised transcription are not big.
# Review 2
> The paper proposes a system for (bass, snare drum, and hi-hat) drum transcription that can be trained on (drum-only) audio alone, without any ground truth transcriptions.
>
> The main idea of constructing a waveform autoencoder whose bottleneck looks like a transcription (by decomposing it into sparse temporal activation sequences for each source, similar to NMF) is a nice one. It can be thought of as a deep-learning version
> of NMF-style unsupervised transcription.
Yup 🙂
> Based on the experiments, the key components which make the system work for transcription appear to be:
> 1. enforcing sparse activtions by using sparsemax nonlinearity to determine
> activations
> 2. making use of features which enhance the onsets of each drum event
>
> Although the training mechanism is unsupervised in the sense that it does not depend on fully transcribed examples, it does require predefined signal templates for each of the targeted instruments.
>
> This is in contrast to NMF-style techniques, which can (sometimes) learn instrument templates along with the transcription.
Just to comment; we need better differentiable synthesizer for this.
> On first read I was surprised that it worked to define the templates at the waveform level, essentially turning the synthesis module F_s into a crude drum machine. It seems that the important tricks to achieve generalization are: randomly useing different “drum-kit” templates in each training batch, and computing the loss in terms of the “onset spectrum”, which discards much of the low level signal detail.
I agree.
> The assumption that the onsets of instrument events can uniquely identify the instrument (as shown in the right of Fig 3) seems limited to certain classes of instruments, e.g. those with percussive attacks. As does (to a lesser extent) the preference for sparsity in activations. That said, the paper does not address the more general transcription task, so this is not a problem.
This is true, and this is one of the reasons the directions of future work should be using better loss function than audio similarity.
(edit: I removed comments on typos/etc.)
# Review 3
> This paper presents an unsupervised method for drum transcription. Overall I believe the idea behind this paper and how it has been undertaken is very good. It is definitely appropriate for the ISMIR conference. However, I do have a couple of major issues and minor issues regarding this paper.
😊
> Major issues
>
> – No mention of system [35] within the background section. The high level usage of a ‘synthesiser’ and a ‘transcriber’ is very similar to the ‘player’ and ‘transcriber’ used in this work. [35] also clearly states that it can be used without existing training data and so is extremely similar to the model proposed in this paper. Why is this paper not mentioned in the background section when it is the paper that shares the most similarity to this work?
For me they are pretty different even on the high level. Having a transcriber module shouldn’t count as something in common in a transcription system. ‘Player’ in [35] generates training data for (supervised) reinforcement learning. I believe I’ve covered enough for the more similar “analysis-synthesis” works in MIR. ..at least as much as I can in within 6-page!
> – The evaluation against other baselines is limited to only the results which make the system look good.
No.
DrummerNet worked well in the experiment that I care.
> Only the results for the eval-cross (trained on DTP) experiment are presented? The evaluation is performed on the MDB and ENST datasets which could be interpreted as a DTP eval-subset scenario.
NO, they’re not. I made it clearer in the camera-ready version, but DrummerNet is not trained on any of SMT/MDB/ENST at all. Hence it’s eval-cross, not eval-subset.
This is from Wu’s review paper.
“Eval Subset: This strategy also evaluates the ADT performance within the ”closed world” of each dataset but using a three-fold subset cross-validation. To this end, each of the three subsets (see Table V) is evenly split into validation and testing sets. The union of all items contained in the remaining two subsets serves as training data. A single subset is used for the validation and testing set in order to maintain sufficient training data.”
> The results for these datasets are presented in Figure 4, but seem to not be discussed further, possibly because the system does not achieve comparable results here. If that is the case it needs to be clearly stated and the possible reasons why discussed so that readers who aren’t familiar with the field get a full understanding of where the contributions are within the larger field.
I’ll probably put more info if there’s space, but (as written in Section 4.3,) we only could do comparison on SMT (Figure 5) because that’s the only option for correct/fair comparison. our experiment is ‘DTD, and eval-cross (trained on DTP)’, and this is only the case of experiment on SMT in the review paper.
I mean..
I cannot compare mine with something that doesn’t exist.
>
> Minor Points:
>
> – I’m not 100% convinced that this system falls under the unsupervised bracket as both the Fs and Fa parts require the user to determine the number of ‘instrument classes’ i.e., K. I would explain somewhere what you mean by the word unsupervised in this context, especially regarding my earlier points about [35].
Is specifying the number of classes considered as supervised?
> – I don’t believe ‘y’ can be called a score, the majority of existing state-of-the-art drum transcription systems do not create a score, only output times in seconds. To achieve a score requires more tasks for example beat and downbeat tracking.
It’s true. But I think it’s fair to say so in the very first sentence of a paper where I introduce about what is transcription as a lay person’s explanation of the task.
(edit: remove comments about typos/grammar)
> – I had to read the DrummerNet section multiple times to fully understand what the system was aiming to do. To aid future readers I believe that a high level explanation of the full system would be useful. For example, you never actually explain what the Fa and Fs system aim to do on a high level.
👍
> – The evaluation and system is limited to the DTD and DTP context. Maybe mention in the future work how the model could be extended for use within the DTM context.
👍 (fun fact: DTM was actually my original task.)
> – This years conference asked for submissions to explicitly discuss reusable insights. It would be useful to add more to the future work section regarding how this model could be incorporated in other work possibly other types of instrument transcription?
👍 (I added a bit more)
Links (again)
This is it. Thanks! Please check out the paper and the code, too.

2 Comments