
THIS POST IS OUTDATED. PLEASE CHECK OUT THIS NEW ONE.
It is highly likely that you don’t need to read the paper after reading this post.
Abstract
We introduce a convolutional recurrent neural network (CRNN) for music tagging. CRNNs take advantage of convolutional neural networks (CNNs) for local feature extraction and recurrent neural networks for temporal summarisation of the extracted features. We compare CRNN with two CNN structures that have been used for music tagging while controlling the number of parameters with respect to their performance and training time per sample. Overall, we found that CRNNs show strong performance with respect to the number of parameter and training time, indicating the effectiveness of its hybrid structure in music feature extraction and feature summarisation.
Summary
1. Introduction
- CNNs (convolutional neural networks) are good useful strong robust popular etc.
- CNNs can learn hierarchical features well.
- Recently, CNNs are sometimes combined with RNNs (recurrent neural networks). We call it CRNN.
- Convolutional layers are used first, then recurrent layers follow to summarise high-level features.
- CRNNs fit music tasks well.
- i) RNNs can be better at aggregation – they are more flexible.
- ii) If input size varies, RNNs rock!
- That’s why we write this paper.
2. Models
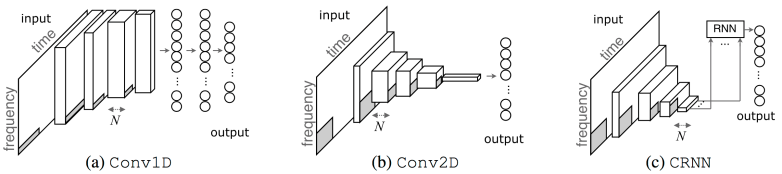
- We compare the three models above.
- We use an identical setting of dropout, batch normalization, activation function (ELU) for a correct comparison.
2.1 Conv1D
- Used in icassp paper and Spotify internship work by Sander.
1D convand1D MaxPooling, then MLP follows.- Assumes non-stationarity of frequency axis
2.2 Conv2D
- I happened to like to use it.
- Deconvolution of 2D conv on music showed 2d patterns.
- Assumes 2D (i.e., time-frequency) patterns in local and global.
- No MLP, so efficient parameters.
2.3 CRNN
- 4-layer
2D convlayers + 2-layerGRUconv: extract local (and short-segment) featuresrnn (gru): summarise those (already quite high-level) features along time- It doesn’t need to be time-axis that RNN sweeps over. It’s just the shape of spectrograms is almost always like that when the prediction is on track-level.
2.4 Scaling networks
- Q. I want to compare them while controlling parameters. How?
- A.
- Don’t change the depth.
- Output node numbers are always fixed.
- I control
widthof layers. What iswidth?- number of nodes in
fully-connectedlayers - number of (hidden) nodes in
gru - number of feature maps in
convlayers
- number of nodes in
- #parameters ∈ {0.1M, 0.25M, 0.5M, 1M, 3M}
- They may seem too small. So, why?
- There are only
50 output nodes. - Hence no need for too many nodes at last
Nlayers.
- There are only
- Is it fair?
- I feel like 0.1M and 0.25M is bit too harsh for
Conv1D. Because it needs a lot of nodes only for fully-connected layers. That’s one of the properties of the network though. RNNlayers inCRNNdon’t need that many hidden parameters, no matter what the total number of parameters is. You will realise it again in the result section.Conv2Dis quite well optimised in this range. In my previous paper (Automatic Tagging using Deep Convolutional Neural Networks), I set the numbers of feature maps too high, resulting in inefficient structure.
- I feel like 0.1M and 0.25M is bit too harsh for
- They may seem too small. So, why?
- A better way?
- Perhaps I will amend this paper for the final version
- Current setting: the same scale factor
sis multiplied to the all layers except output layer. E.g.,scan be numbers like0.3,0.9,1.3. - Proposed setting: set
s, but for layers near output layer, I usedsqrt(s).- i.e.
layer widthvaries less as it is close to output layer. - Because #output layer node is fixed.
- i.e.
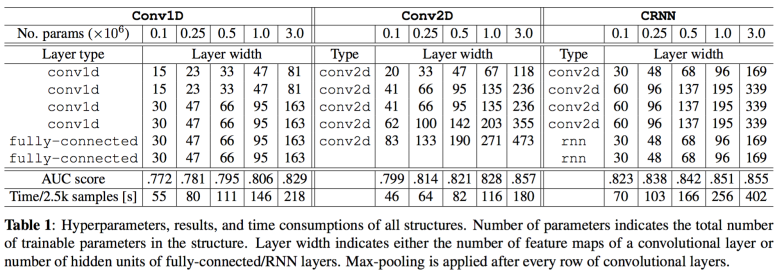
3. Experiments
- MSD is used, Top 50 tag is predicted
- 29s subsegment, 12kHz down-sampled, 96-bin mel-spectrogram
- keras, theano, librosa.
- AUC-ROC for evaluation
3.1 Memory-controlled experiment
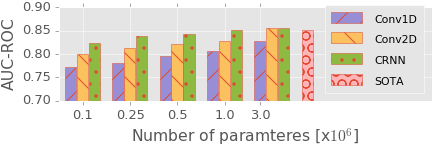
CRNN>Conv2D>Conv1Dexcept 3.0M parametersCRNN>Conv2D:RNN rocks. Even with narrower conv layers,CRNNshows better performance.- Convolution operation and max-pooling is quite simple and static, while recurrent layers are flexile on summarising the features. Actually, we don’t know exactly how they should summarise the information. We only can say RNN seems better at it. Well, considering its strong performance in sentence summarisation, it’s not surprising.
Conv2D>Conv1D- Fully-connected layers don’t behave better – easily overfit, takes large number of parameters. Looks like the gradual subsampling over time and frequency axis in
Conv2Dis working well. - There can be many variants between them. E.g., why not mixing
1d convlayers +2D sub-sampling? It’s out of the scope here though.
- Fully-connected layers don’t behave better – easily overfit, takes large number of parameters. Looks like the gradual subsampling over time and frequency axis in
3.2 Computation-controlled experiment
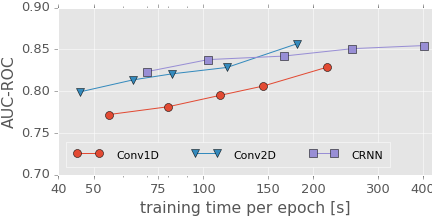
- Same result but plotted in time-AUC domain
- In training time < 150,
CRNNis the best. Conv2D(3M-parameter) is better in time > 150- Okay, [DISCLAIMER]
- As described in paper, I wait much longer for 3M-parameter structures because I want them to show their best performance, a reference structure.
- They were trained MUCH LONGER than #parameters <= 1M.
- Therefore it’s not fair to compare the others to 3M-params.
3.3 Performance per tag
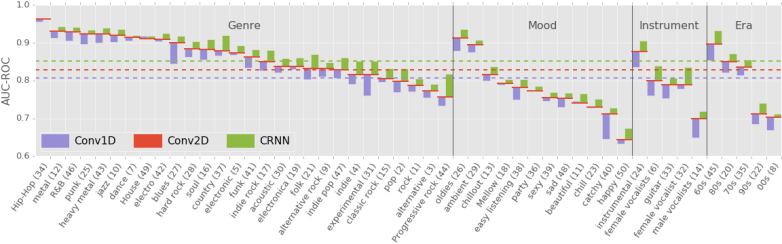
Fig. 3: AUCs of 1M-parameter structures. i) The average AUCs over all samples are plotted with dashed lines. ii) AUC of each tag is plotted using a bar chart and line. For each tag, red line indicates the score of Conv2D which is used as a baseline of bar charts for Conv1D (blue) and CRNN (green). In other words, blue and green bar heights represent the performance gaps, Conv2D-Conv1D and CRNN-Conv2D, respectively. iii) Tags are grouped by categories (genre/mood/instrument/era) and sorted by the score of Conv2D. iv) The number in parentheses after each tag indicates that tag’s popularity ranking in the dataset.
- AUCs per tags (1M params structures)
CRNN>Conv2Dfor allConv2D>Conv1Dfor 47/50
- Let’s frame tagging problem as a multi-task problem.
- A better structure in a task A is a better structure for other tasks as well.
- Tag popularity (=#occurrence of each tag) is not correlated to the tag performances. Therefore their different performance is mainly not about popularity bias.
4. Conclusion
- There is a trade-off in speed and memory
- Either
Conv2DandCRNNcan be used depending on the circumstance.
5. Github
https://github.com/keunwoochoi/music-auto_tagging-keras provides Conv2D and CRNN structure and pre-trained weights. Their performances are better than the paper because I didn’t use early stopping for this repo and waited like forever.
Oh, and again, here’s a link to the paper.

The GitHub link is broken !
LikeLiked by 1 person
Thanks! I fixed it.
LikeLike
The Conv1D architecture looks odd in the diagram – the layer 1 filters should span the full height of the mel-spectrogram otherwise this is still 2D convolution.
LikeLike
Hi, actually that’s true. An updated version will be posted very soon 🙂
LikeLike
What tool did you use to draw the “performance per tag” graph?
LikeLike
Just python and matplotlib.
LikeLike
can you pls share your evaluation code? I tried to reproduce your model with your weights on magnatagatune dataset in torch. But my AUC scores are lesser ..
LikeLike
Hi, I just used roc_auc_score in scikit-learn. I only shared weights on MSD, not MagnaTagATune and the tag sets are not identical. How did you use it for MTT?
LikeLike
Oh, even I use the metric in scikit-learn. Yea tags are not same.. I just initialized your weights and started finetuning on MTT.
LikeLike
maybe you should try ‘compace_cnn’ folder of the repo rather than two older ones.
LikeLiked by 1 person
Do you have MTT weights? Its painful to download MSD ..
LikeLike
I ment, its painful to download MSD dataset
LikeLike
No, but why would you want MTT weights when it’s painful to download MSD? 🙂
LikeLike
Im doing my paster thesis and I want to test the performance on specific tags.. So I just wanted to replace few tags in your network and fine tune..
LikeLike
Yeah, which you can do with either MTT or MSD weights. Try compact_cnn! It worked quite well on many tasks.
LikeLiked by 1 person
Yea technically either weights should work but auc diverges after 2 MTT epoch.. well yes I ll try out the compact_cnn
LikeLike
Also it would be worth trying something other than neural networks. E.g. SVM, random forest, etc. Good luck!
LikeLiked by 1 person